SELECT newid()
Выдает каждый раз случайное число:
Если интересно, пример с использованием newid() в задаче распределения клиентов по менеджерам (/задач по исполнителям)
Случайное распределение
(пример выполнен на базе данных AdventureWorks (см. Примеры БД MS SQL Server)
USE AdventureWorks
GO
--есть список клиентов и территорий
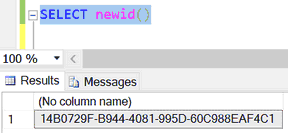
SELECT CustomerID, TerritoryID FROM [Sales].[Customer]
--для наглядности берём одну какую-то территоррию и несколько каких-то клиентов:
WHERE TerritoryID = 4 AND CustomerID IN (3, 4, 5, 6, 21, 23, 24, 25)
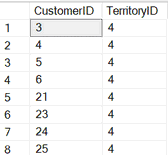
--есть список менеджеров и территорий
SELECT TerritoryID, SalesPersonID FROM [Sales].[SalesPerson]
WHERE TerritoryID = 4
--Задача по каждой территории распределить клиентов между менеджерами
--на каждого CustomerID выбрать одного SalesPersonID, который работает на той же территории
--распределение может быть +/- неравномерным -- это не критично
--РЕШЕНИЕ
--1. Вывести случайное число напротив каждого SalesPersonID
SELECT SalesPersonID, newid() AS rnd FROM [Sales].[SalesPerson]
WHERE TerritoryID = 4
order by rnd

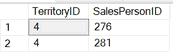
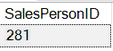
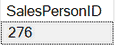
--2. Вывести одного SalesPersonID также в случайном порядке
SELECT top 1 SalesPersonID FROM [Sales].[SalesPerson]
WHERE [Sales].[SalesPerson].TerritoryID = 4
order by newid()
С каждым новым выполнением этого запроса менеджеры будут чередоваться (иногда повторяться):
 /
/  / ...
/ ...
--3. Вывести клиента, территорию и случайного менеджера
--ЗАПРОС РАСПРЕДЕЛЕНИЯ
SELECT CustomerID, TerritoryID,
(SELECT top 1 SalesPersonID FROM [Sales].[SalesPerson]
WHERE [Sales].[SalesPerson].TerritoryID = [Sales].[Customer].TerritoryID
order by newid(),
CustomerID -- зачем второй элемент в order by:
--Оптимизатор кэширует под-запрос (потому что подзапрос не меняет результата в зависимости
--от TerritoryID пока не произойдет запроса во внешнее выражение (это такое предположение)).
--Если не заставить оптимизитора перестать кэшировать под-запрос, то для всех клиентов будет один и тот же
--какой-то менеджер, а это не то, что в задаче (в задаче -- распределить клиентов по всем менеджерам).
--Можно по-разному заставить оптимизатора не кэшировать под-запрос, например, в выражение newid()
--добавить concat(newid(), CustomerID) или добавить CustomerID в order by
--Короче, любым способом заставить запросить что-то из внешнего выражения.
) AS SalesPersonID_random
FROM [Sales].[Customer]
WHERE TerritoryID = 4 AND CustomerID IN (3, 4, 5, 6, 21, 23, 24, 25)
С каждым новым выполнением этого запроса результат может быть разным. Равномерным:
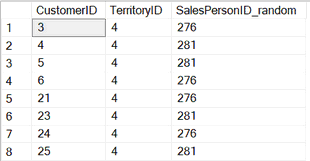
Или неравномерным (в любом порядке неравномерности):
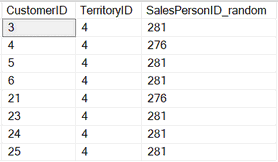
--4. Проверить:
SELECT TerritoryID, SalesPersonID_random, COUNT(*) FROM (
SELECT CustomerID, TerritoryID,
(SELECT top 1 SalesPersonID FROM [Sales].[SalesPerson]
WHERE [Sales].[SalesPerson].TerritoryID = [Sales].[Customer].TerritoryID
order by newid(), CustomerID) AS SalesPersonID_random
FROM [Sales].[Customer]
WHERE TerritoryID = 4 AND CustomerID IN (3, 4, 5, 6, 21, 23, 24, 25)
) AS grouped
GROUP BY TerritoryID, SalesPersonID_random
order by TerritoryID
С каждым новым выполнением этого запроса тот же разный результат:
 /
/  / ...
/ ...
Если интересно, есть пример решения этой же задачи, но со стабильным равномерным распределением:
➢Равномерное (карусельное) распределение одних записей вдоль других